Other products
ROBOTCORE Framework
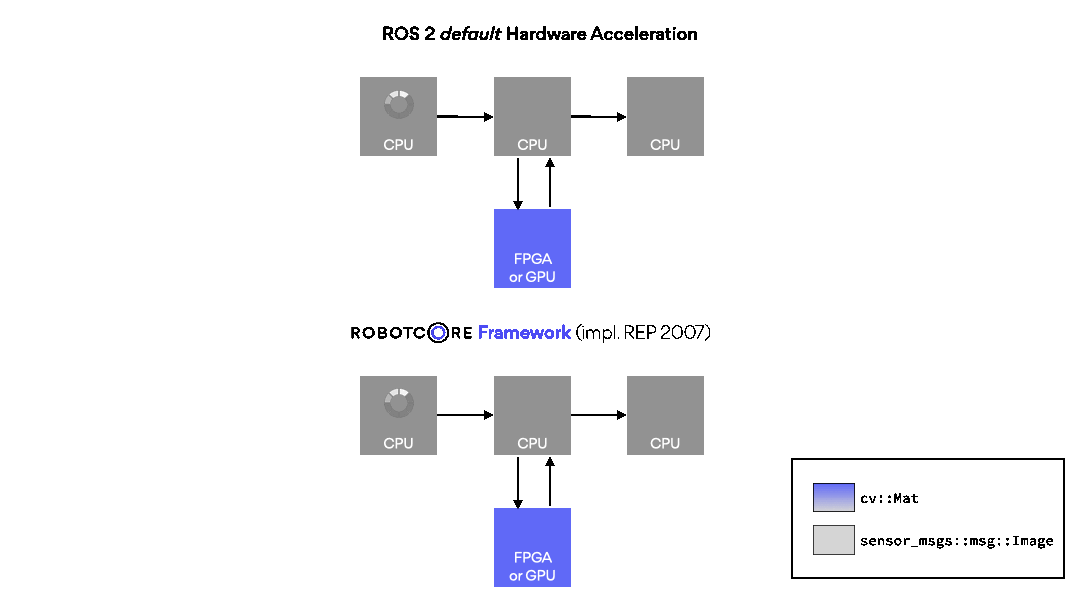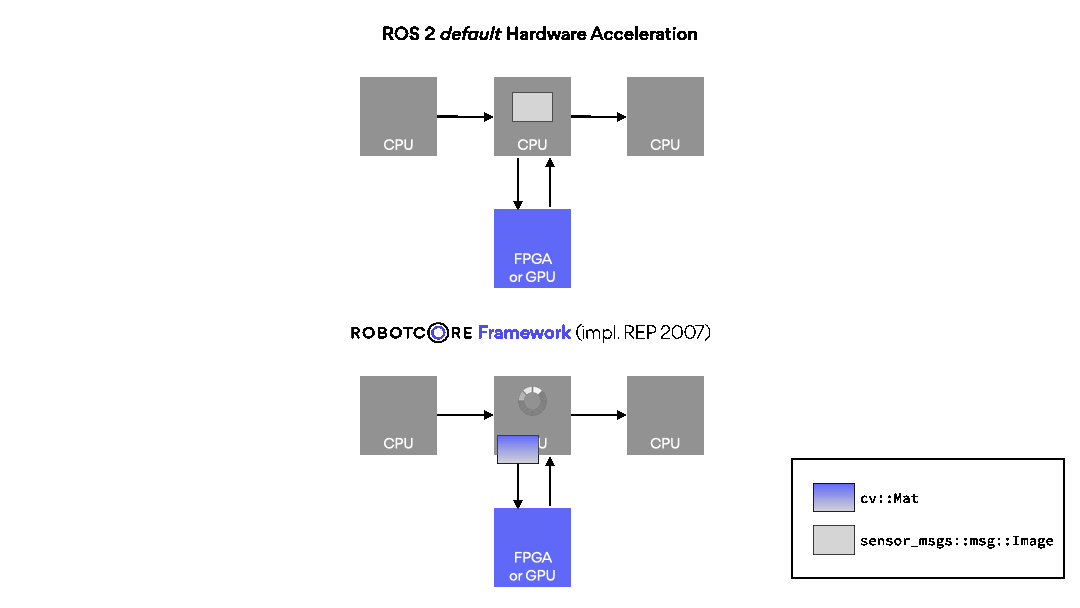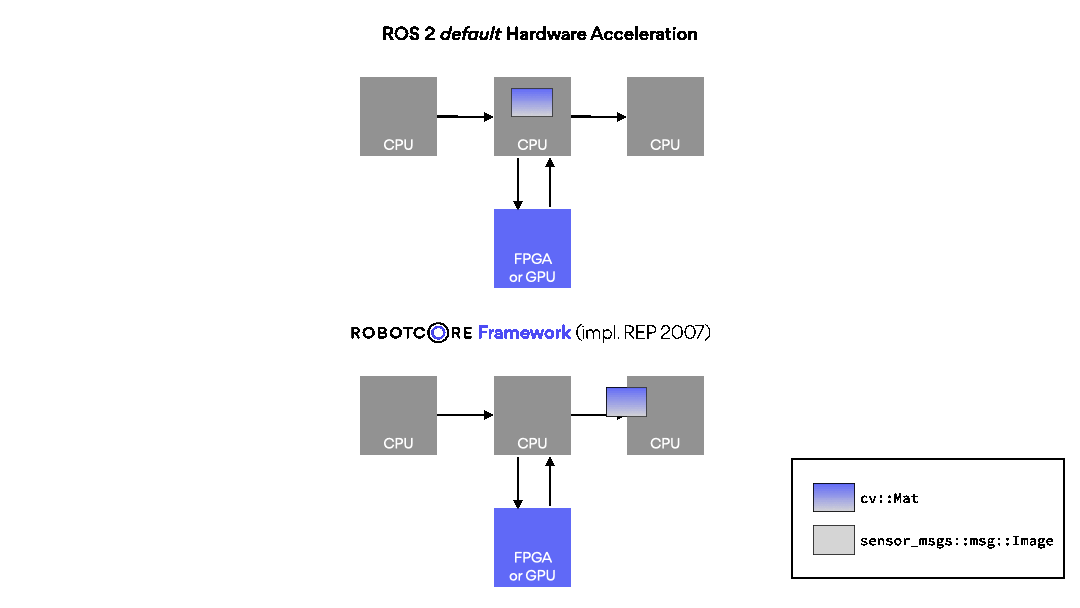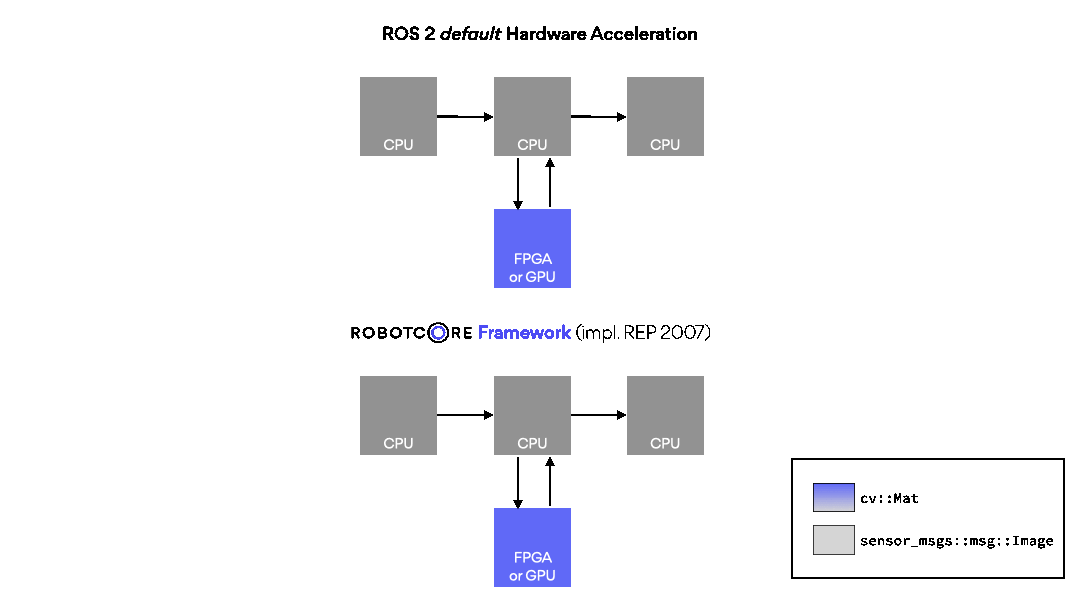
FPGA and GPU hardware acceleration framework for ROS
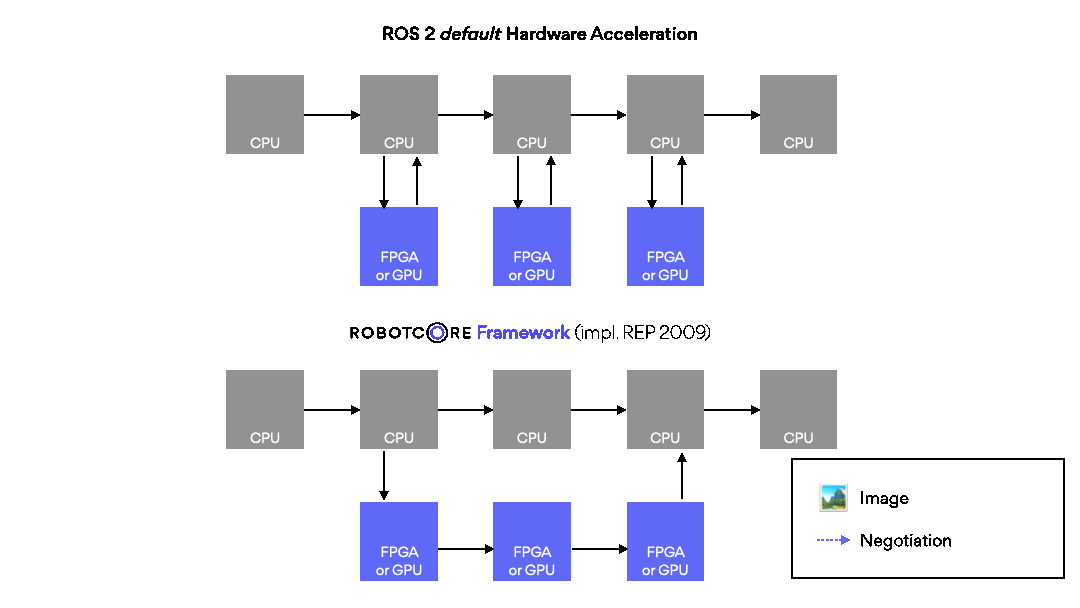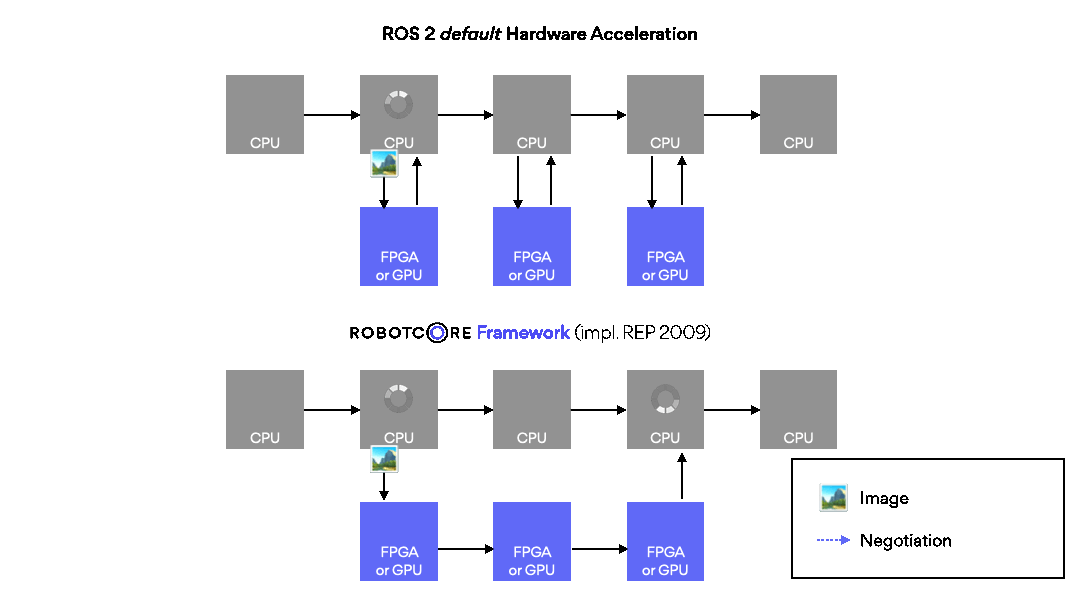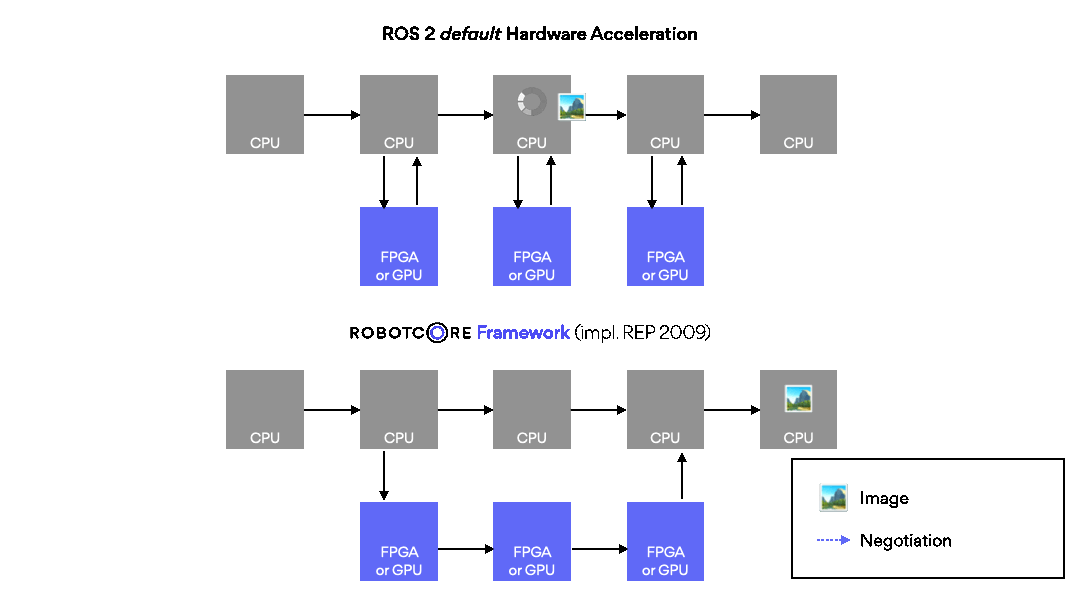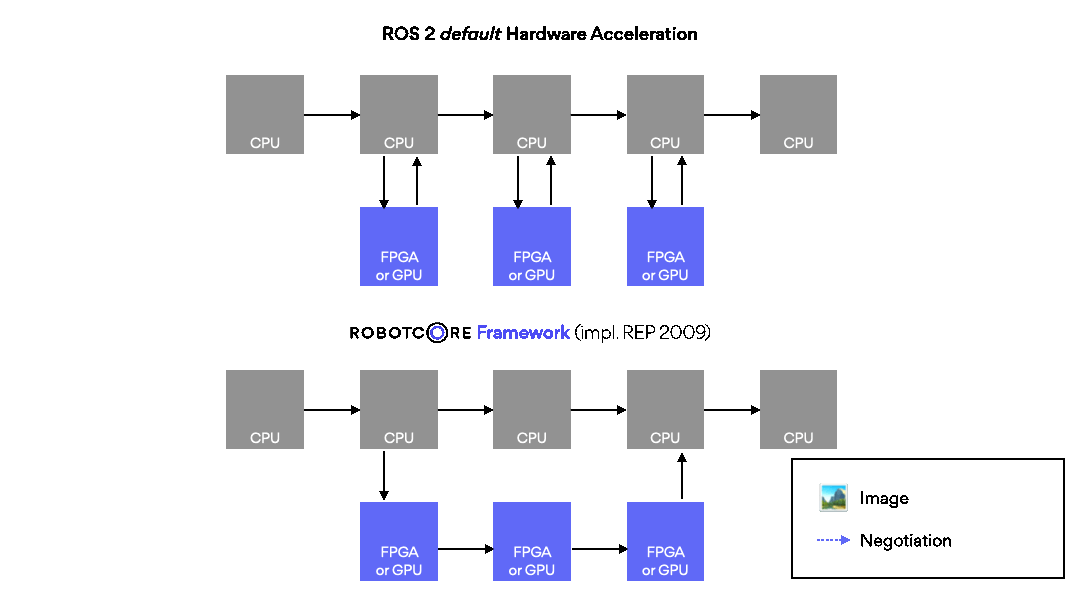
ROBOTCORE® Framework helps build custom compute architectures for robots, or IP cores, directly from ROS workspaces without complex third-party tool integrations. Make your robots faster, more deterministic and/or power-efficient. Simply put, it provides a vendor-agnostic development, build and deployment experience for creating robot hardware and hardware accelerators similar to the standard, non-accelerated ROS development flow.
Get ROBOTCORE® Framework Read the paper