Other products
ROBOTCORE Perception
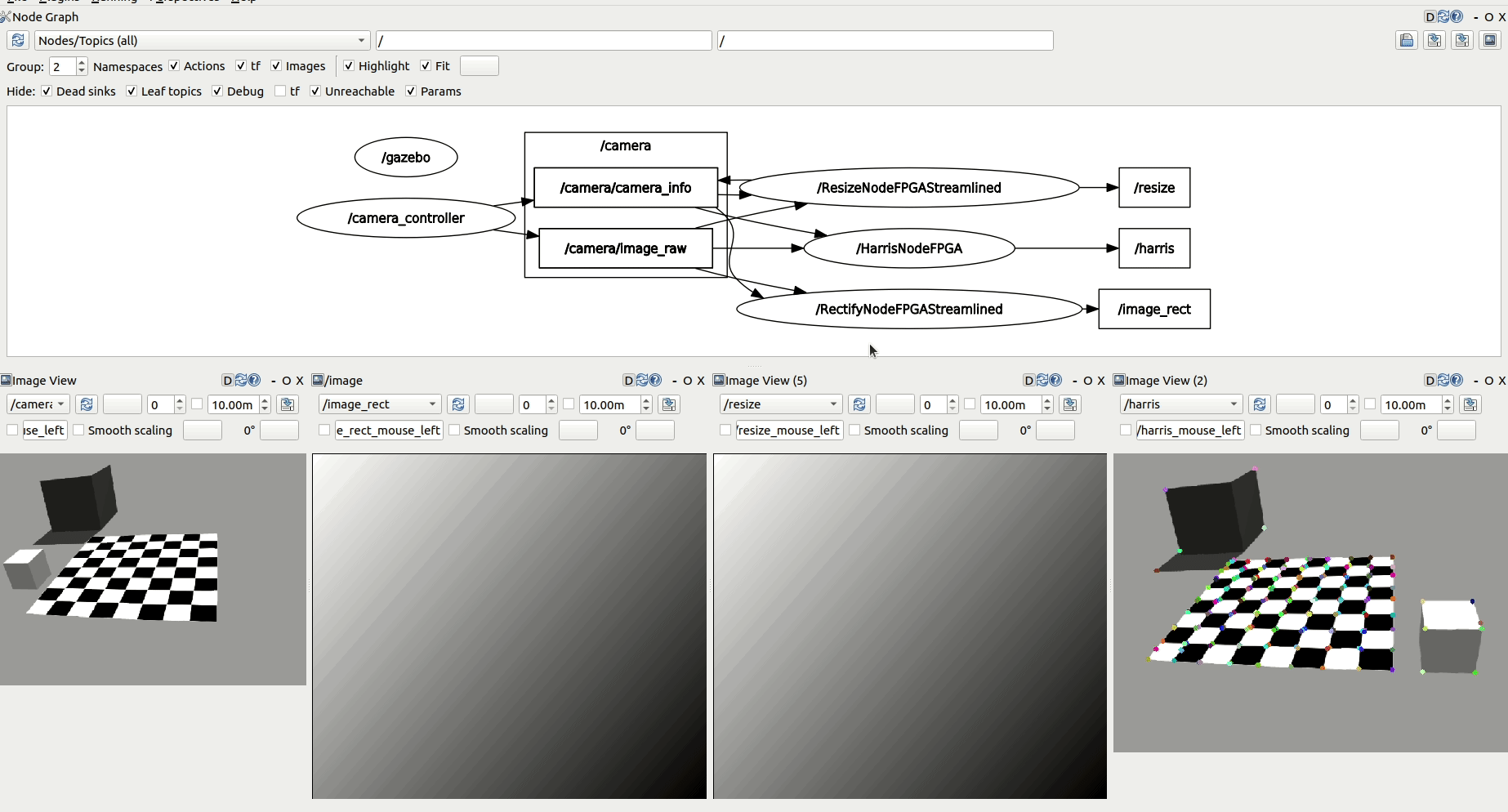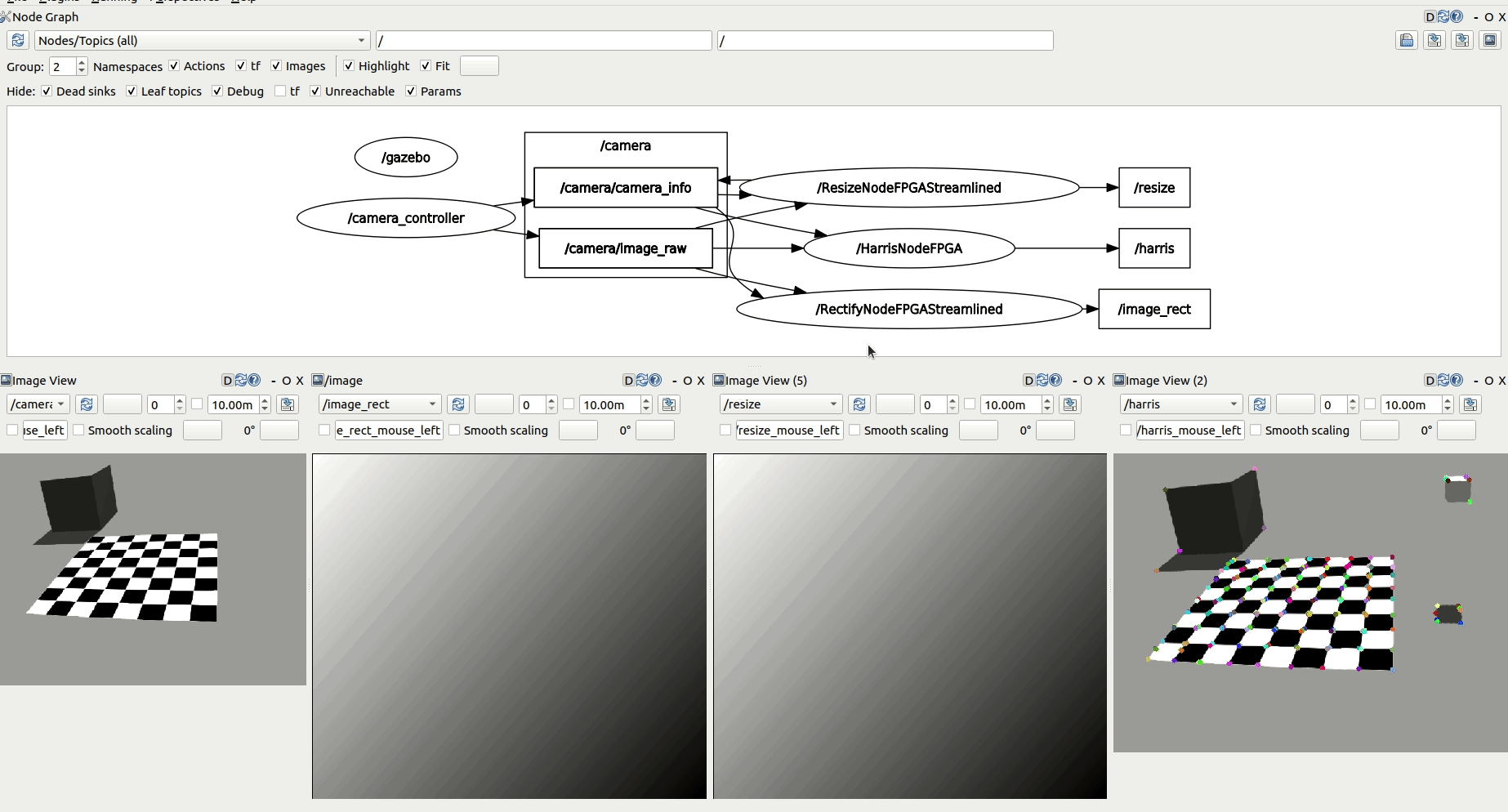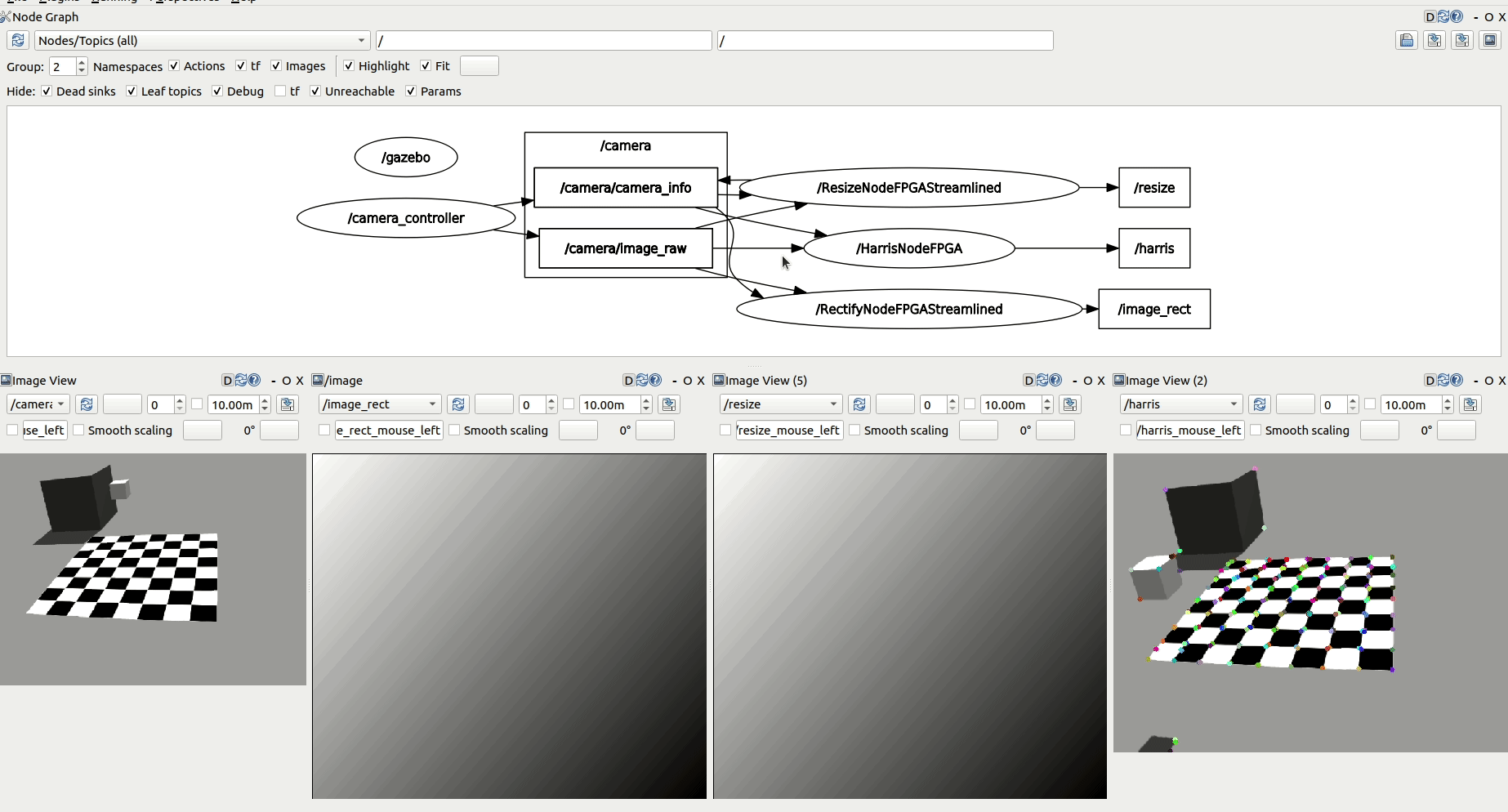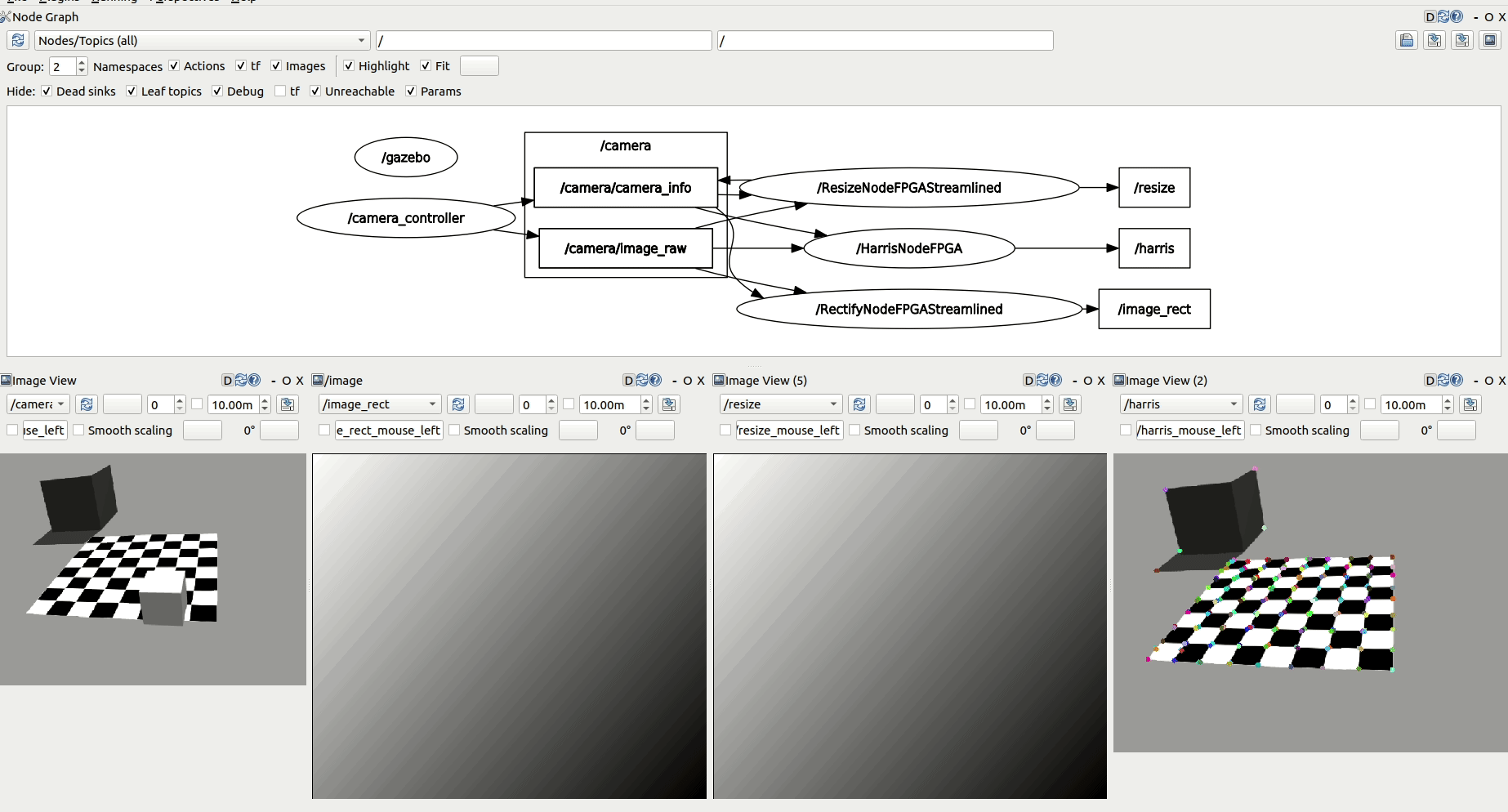
Speed up your ROS robotics perception pipelines
ROBOTCORE Perception is an optimized robotic perception stack that leverages hardware acceleration to provide a speedup in your perception computations. API-compatible with the ROS 2 perception stack, ROBOTCORE Perception delivers high performance, real-time and reliability to your robots' perception.
Get ROBOTCORE® Perception Perception consulting