CPUs
(group 1) 12-Core 64-bit Arm® Cortex®-A78 CPU 3MB L2 + 6MB L3 (CPU Max Freq 2.2 GHz)
(group 2) 4-Core 64-bit Arm® Cortex®-A53 (CPU Max Freq 1.5 GHz)
(group 2) 2-Core 32-bit Arm® Cortex-R5F real-time processor (CPU Max Freq 600MHz)
GPU
NVIDIA Ampere architecture with 2048 NVIDIA® CUDA® cores and 64 Tensor Cores (GPU Max Freq 1.3 GHz)
FPGA
256K System Logic Cells, 1248 DSPs, 26.6Mb on-chip memory (LUT: 117K, FF: 256K, DSP: 1248, BRAM: 144, URAM: 64)
Machine Learning throughput
275 TOPS
Memory
(group 1) 64GB 256-bit LPDDR5 (204.8 GB/s)
(group 2) 4GB 64-bit DDR4
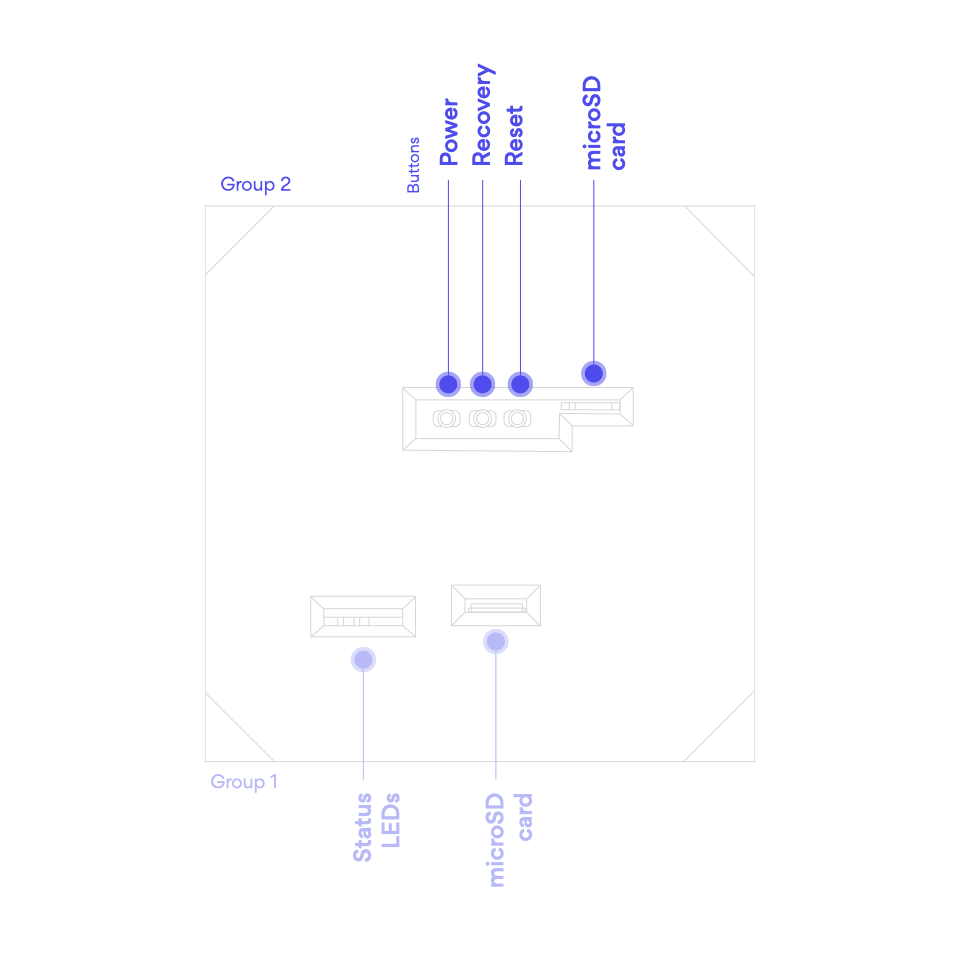
Disk storage
(group 1) 64GB eMMC
(groups 1 and 2) SDHC card (external storage)
Thermal cooling
Active (Fan + Heatsink)
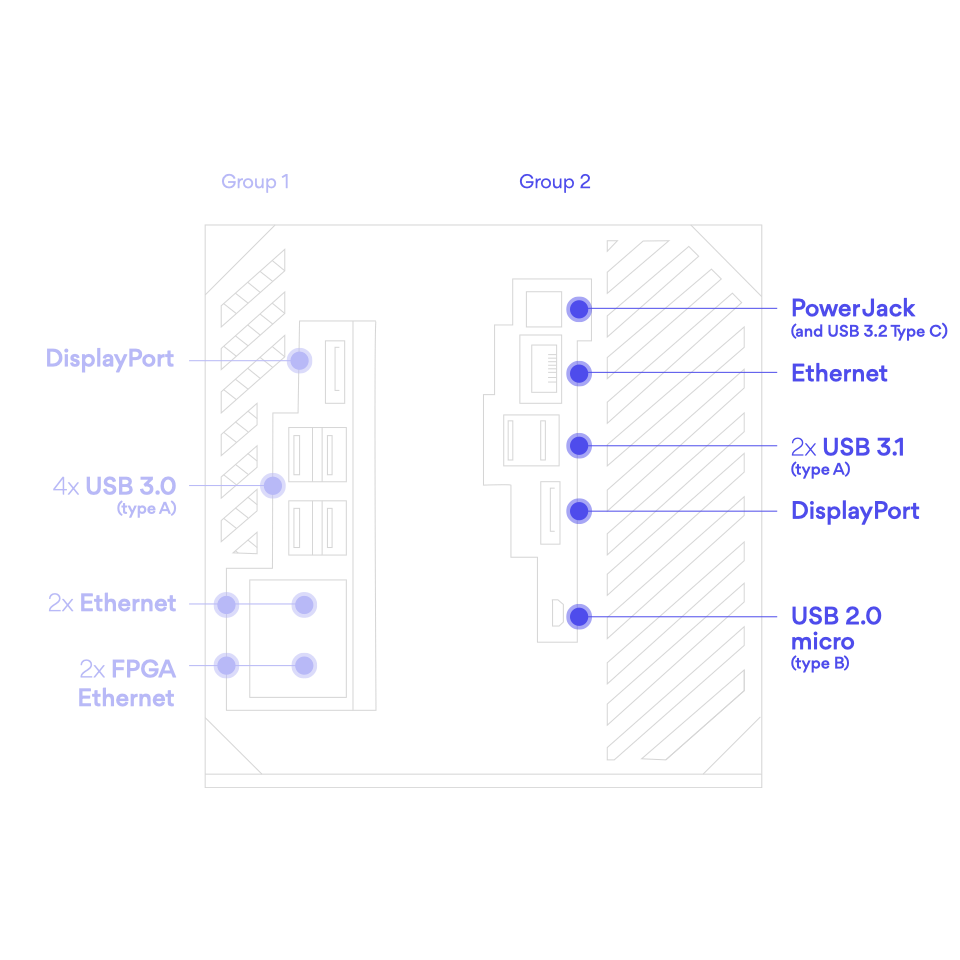
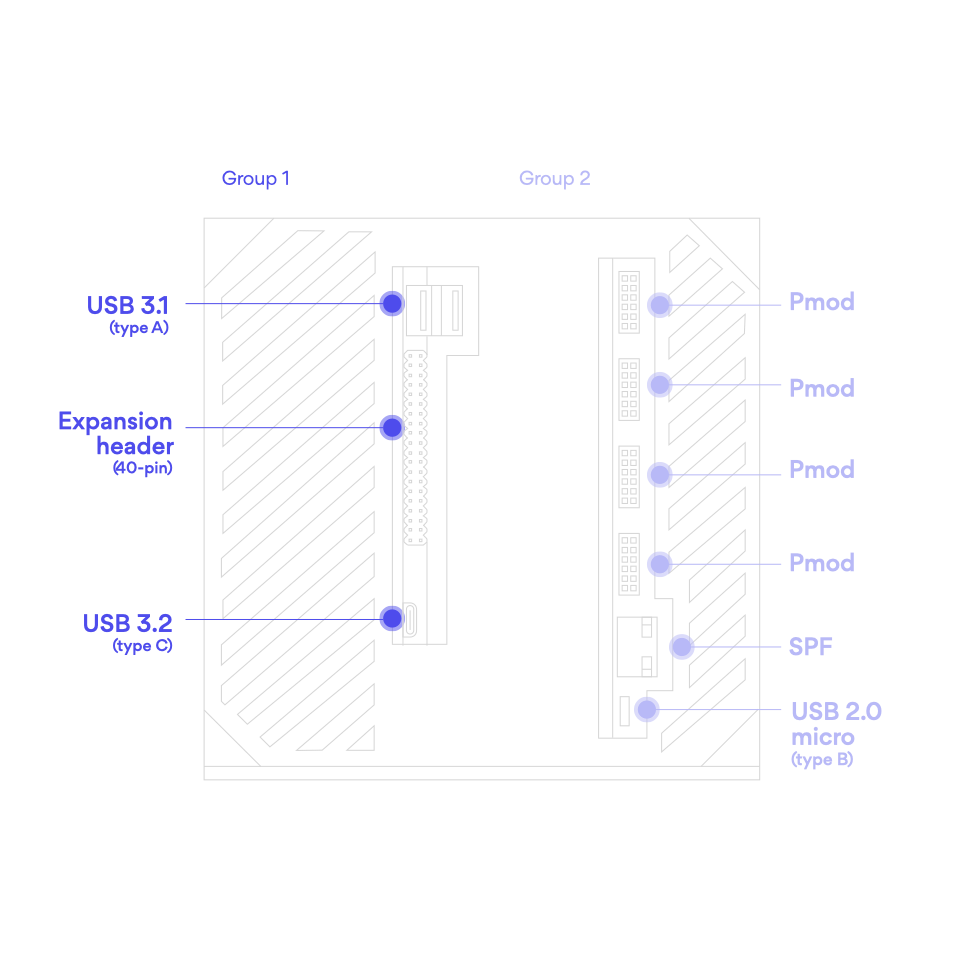
I/O
USB 2.0, SD/SDIO, UART, CAN 2.0B, I2C, SPI, GPIO, EtherCAT
High-speed I/O
PCIe® Gen2, USB3.0, SATA 3.1, DisplayPort, Gigabit Ethernet, 2x Time Sensitive Networking (TSN) Ethernet
Hardware synchronization (PTP)
sub-microsecond precision (<1 us)
Interconnect between group 1 and group 2
Ethernet-based