Other products
ROBOTCORE Transform
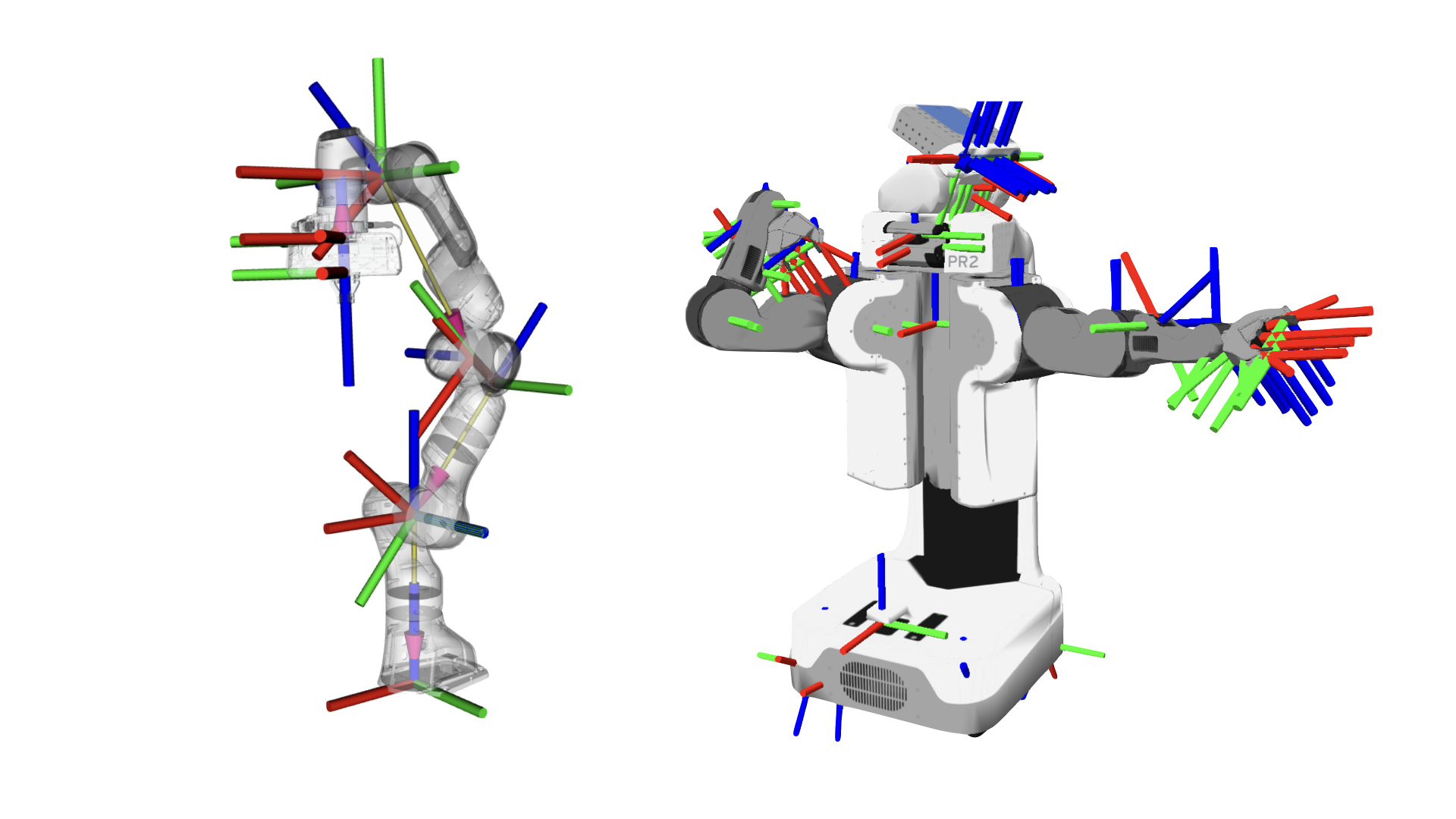
Speed up your ROS Coordinate System Transformations (tf)
ROBOTCORE Transform is an optimized robotics transform library that manages efficiently the transformations between coordinate systems in a robot. API-compatible with the ROS 2 transform (tf2) library, ROBOTCORE Transform delivers higher throughput and lower latency while aligning with the standard way to keep track of coordinate frames and transform data within a ROS robotic system.
Get ROBOTCORE® Transform Robotics consulting?